{kind=link}
I just finished assembling two BILLY Ikea bookcases (with their extension units) in a row (to capitalize on the (somewhat minimal) learning and memory inertia involved), and I got to admit that I found the process rather enjoyable, and almost pythonic in nature. I don't know if it has always been the case (I suspect it must be the result of a long evolution, with lots of trial and error), but I found the assembly instructions to be so clear, so minimal (with their visual-only language), so logical (with positive, as well as negative advices, very importantly) that it's almost impossible to make hard to unwind (or worst, unrecoverable) errors, if you take time to study them carefully. I had to write about it, and so I highly recommend Ikea assembling for a relaxing moment, away from more complicated and abstract intellectual problems.
Sunday, June 24, 2012
Monday, June 18, 2012
Hello 6510!
The way I see it, modern-day C=64 hacking is the epitome of "autotelic computing" (a fancy new word I just learned, which seemed to capture so perfectly one of my deepest intellectual ideals, I couldn't resist renaming my blog).
Like so many programmers of the current generation, I've been a long time C=64 hacker, very autotelic to boot. As soon as I realized that BASIC V2 was not very appropriate for game programming, I had to learn 6510 assembly. But for a French-speaking ~12 year-old, this is no easy task. With the help of a forgotten library book I was very lucky to find, I was able achieve a few proofs of concept, but not much more (sadly no Super Mario, King's Quest, U.N. Squadron or Power Drift clone, contrary to my wildest dreams).
Nevertheless, I've been following with interest the many aspects of the nostalgia-fueled C=64 subculture that has been thriving exponentially with the internet in the last two decades: numerous emulators, game repositories, compilers, SID-based chiptune revival, etc. Fascinating stuff, driven mostly by the unflinching love of this old machine!
Recently I got an idea for an autotelic project, that I won't disclose now, because it's not very likely to ever materialize (or should I say logicalize?). But to gently push it towards reality anyway, I thought I'd share and document my very first Hello World attempt with modern C=64 tools.
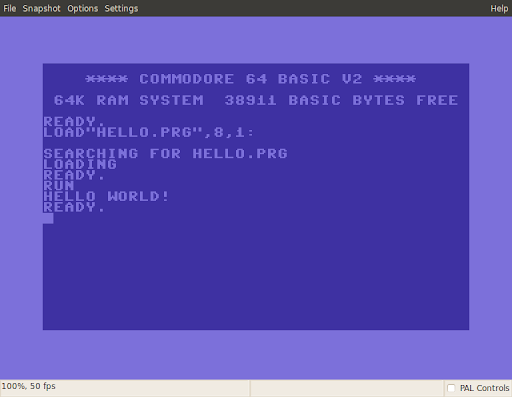
Why would you torture yourself with a bare-metal (or emulated) assembler when you can use such a powerful tool as the aptly named Kick Assembler? Java-based, command-line driven, sporting some augmented syntax and parsing capabilities, a higher-level scripting engine, etc. In fact this fine piece of engineering made me realize my own "shopping habits" when contemplating the adoption of a new software package: whenever I can find, within the first five pages of the manual, how to achieve the initial task I have in mind, I'm instantly sold. And that's precisely what happened with this one, as this assembly code snippet (adapted very slightly from Jim Butterfield's excellent book Learning Machine Code Programming on the Commodore 64) shows (that book, and better English courses perhaps, could have possibly stirred my game programming career otherwise):
which is very easy to pipe directly in an emulator (I use x64 on Ubuntu):
yielding the nostalgic and familiar (but feeling so cramped nowadays, don't you find?):
This post may (or may not..) be followed by posts in the same vein.
Update: my original idea was way more ambitious, but I ended up writing this Tetris clone, to learn C=64 assembly. Without help from the Lemon64 community, things would have been undeniably harder. If someone is interested, I could consider writing about it, tutorial-style.
Like so many programmers of the current generation, I've been a long time C=64 hacker, very autotelic to boot. As soon as I realized that BASIC V2 was not very appropriate for game programming, I had to learn 6510 assembly. But for a French-speaking ~12 year-old, this is no easy task. With the help of a forgotten library book I was very lucky to find, I was able achieve a few proofs of concept, but not much more (sadly no Super Mario, King's Quest, U.N. Squadron or Power Drift clone, contrary to my wildest dreams).
Nevertheless, I've been following with interest the many aspects of the nostalgia-fueled C=64 subculture that has been thriving exponentially with the internet in the last two decades: numerous emulators, game repositories, compilers, SID-based chiptune revival, etc. Fascinating stuff, driven mostly by the unflinching love of this old machine!
Recently I got an idea for an autotelic project, that I won't disclose now, because it's not very likely to ever materialize (or should I say logicalize?). But to gently push it towards reality anyway, I thought I'd share and document my very first Hello World attempt with modern C=64 tools.
Why would you torture yourself with a bare-metal (or emulated) assembler when you can use such a powerful tool as the aptly named Kick Assembler? Java-based, command-line driven, sporting some augmented syntax and parsing capabilities, a higher-level scripting engine, etc. In fact this fine piece of engineering made me realize my own "shopping habits" when contemplating the adoption of a new software package: whenever I can find, within the first five pages of the manual, how to achieve the initial task I have in mind, I'm instantly sold. And that's precisely what happened with this one, as this assembly code snippet (adapted very slightly from Jim Butterfield's excellent book Learning Machine Code Programming on the Commodore 64) shows (that book, and better English courses perhaps, could have possibly stirred my game programming career otherwise):
:BasicUpstart2(start) // autostart macro start: ldx #$00 // put 0 in X register loop: lda $4000,x // put X-indexed char of string (stored at $4000) in acc jsr $ffd2 // call CHROUT kernal routine to print single char in acc inx // increment X cpx #12 // did we reach the 12th char? bne loop // if not, loop again rts // if yes, terminate .pc = $4000 "data" .text "HELLO WORLD!"
$ java -jar KickAss.jar hello.asm -execute x64

This post may (or may not..) be followed by posts in the same vein.
Update: my original idea was way more ambitious, but I ended up writing this Tetris clone, to learn C=64 assembly. Without help from the Lemon64 community, things would have been undeniably harder. If someone is interested, I could consider writing about it, tutorial-style.

Sunday, June 17, 2012
Two Tales of Data Clerking
I - A couple of years ago..
I was tasked with the creation of a web-based medical database application to manage TB case data. As the data had spatial components, the choice of a database tech (PostgreSQL, with its PostGIS extension) was easy. For the client-side tech (mostly data entry forms coming from the paper world), the choice was harder. After having explored and reviewed many frameworks, I finally settled for the powerful Ext JS library. Lastly, as I wanted to code the server-side logic in Python, I decided to go with mod_python, which wasn't then in the almost defunct state it is in today. I played for a while with the idea of a more integrated environment like Django, but I decided to go without after having realized that the mildly complicated database logic I had in mind was not well supported by an ORM. In its place, I devised little_pger, a very simple, psycopg2-based "proto-ORM", wrapping common SQL queries in a convenient and pythonic interface (at least to my taste!).Having made all these choices, I was ready to build the application. I did, and in retrospect, it's very clear that the most time-consuming aspect, by far, was the delicate user interface widgets I had to create to maximize user happiness and data consistency (with all the power Ext JS yields, it's hard to resist):
- Different kinds of autocompletion text fields
- Panels with variable number of sub-forms
- Address validation widget
- Etc..


The initial versions of the app were so heavy that I had to revise the whole UI architecture.. but then a nice thing happened: the JavaScript performance explosion brought by the browser war.. suddenly this wasn't a concern anymore!
This system has been working very reliably (from an Ubuntu VM) since then. It has required slightly more user training and adjustments than I'd assumed (sophisticated UI semantics is always clearer in the designer's mind) but it is still being used, and its users are still (seemingly) happy, and so this could have been the end of an happy, although rather uneventful story, if it wasn't for the fact that I actually spent some time meditating upon what I'd do differently, being offered the opportunity.
For instance, learning about WSGI, but above all, the very elegant Flask microframework, made me want to be part of the fun too. So I refactored my application in terms of it (which was mostly painless). So long mod_python..
By then however, a kind of "UI fatigue" had begun to set in, and when I was asked to quickly code an addon module, I admit it: I did it with Django (and no one really noticed).
Time passed, I worked on many other projects and then it came again.
II - A couple of months ago..
I was asked to create a medical database to hold vaccination survey data. By that time, I had developed another condition: "database fatigue" (AKA obsessive-compulsive normalization), which is probably better explained by these schema diagrams from my previous app:

And so, even though I still strongly believed in the power of relational databases, as the NoSQL paradigm was gaining traction, MongoDB seemed like a fun alternative to try.
This time however, as I lacked the courage (or ignorance) I had when facing the prospect of "webifying" 47 pages of paper forms (though it was only a mere 13 pages for this new task), I decided to explore other options. The solution I came up with is based on a kind of "end user outsourcing": since the paper form was already created as a PDF document, all I did was superimpose dynamic fields on it, and added a big "Submit" button on top (attached to a bit of JS that sends the form payload over HTTP). Of course this is not web-based anymore (rather HTTP-based), and it makes for a less sophisticated user experience (e.g. no autocompletion fields), but that's the price to pay for almost pain-free UI development. So long, grid and accordion layouts..


The really nice thing about it is hidden from the user's view: the entire application server reduces to this Python function (resting of course on the immense shoulders of Flask and PyMongo), which receives the form data (as a POST dict) and stores it directly in the MongoDB database, as a schemaless document:
from flask import * from pymongo import * application = Flask('form_app') @application.route('/submit', methods=['POST']) def submit(): request.parameter_storage_class = dict db = Connection().form_app db.forms.update({'case_id': request.form['case_id']}, request.form, upsert=True, safe=True) return Response("""%FDF-1.2 1 0 obj << /FDF << /Status (The form was successfully submitted, thank you!) >> >> endobj trailer << /Root 1 0 R >> %%EOF """, mimetype='application/vnd.fdf')
Of course these database app designs are so far apart that it could seem almost dishonest to compare them. But the goal was not to compare, just to show that it's interesting and sometimes fruitful to explore different design options, when facing similar problems.
Subscribe to:
Posts (Atom)